Thank you for your impressive effort in building this model.
I was testing batch variant prediction focusing on the CAGI5 TERT GBM promoter challenge set, using 2KB context window and DNase/ATAC/CAGE head. One thing I noticed is that the prediction across different run could vary a lot, especially if I try to rank which biosample_name produces the best Prediction-Observation correlation. And sometimes the best Prediction-Observation correlation could vary from 0.8 to 0.6.
I wonder whether the randomness is mostly due to the ensemble scorer / ensemble model (I thought only the student model is used in variant scoring?) or something related to just random seed setting? Would you recommend run multiple times to get a distribution of prediction in practice?
Also it seems that the context length do have an impact on prediction even if variant scorer is fixed. That’s expected but maybe it’s good to add a note in the jupyter notebook (e.g. suggest to use shorter context when studying local effect, as in MPRA).
Welcome @Xi_Fu to the forum, and thanks for your message!
So there is some stochasticity when making predictions due to GPU numerics not being guaranteed to be deterministic. We shouldn’t have any random seeds in our inference pipeline (though there is some stochasticity with calibrated variant scores), and no we don’t do model ensembling, the ALL_FOLDS model uses our single, distilled model.
In practice we haven’t found this variance to matter too much when benchmarking, but we rarely run with short intervals… Would you be able to share any particular examples where the prediction is notably different? A 0.6-0.8 change in correlation does sound less than ideal!
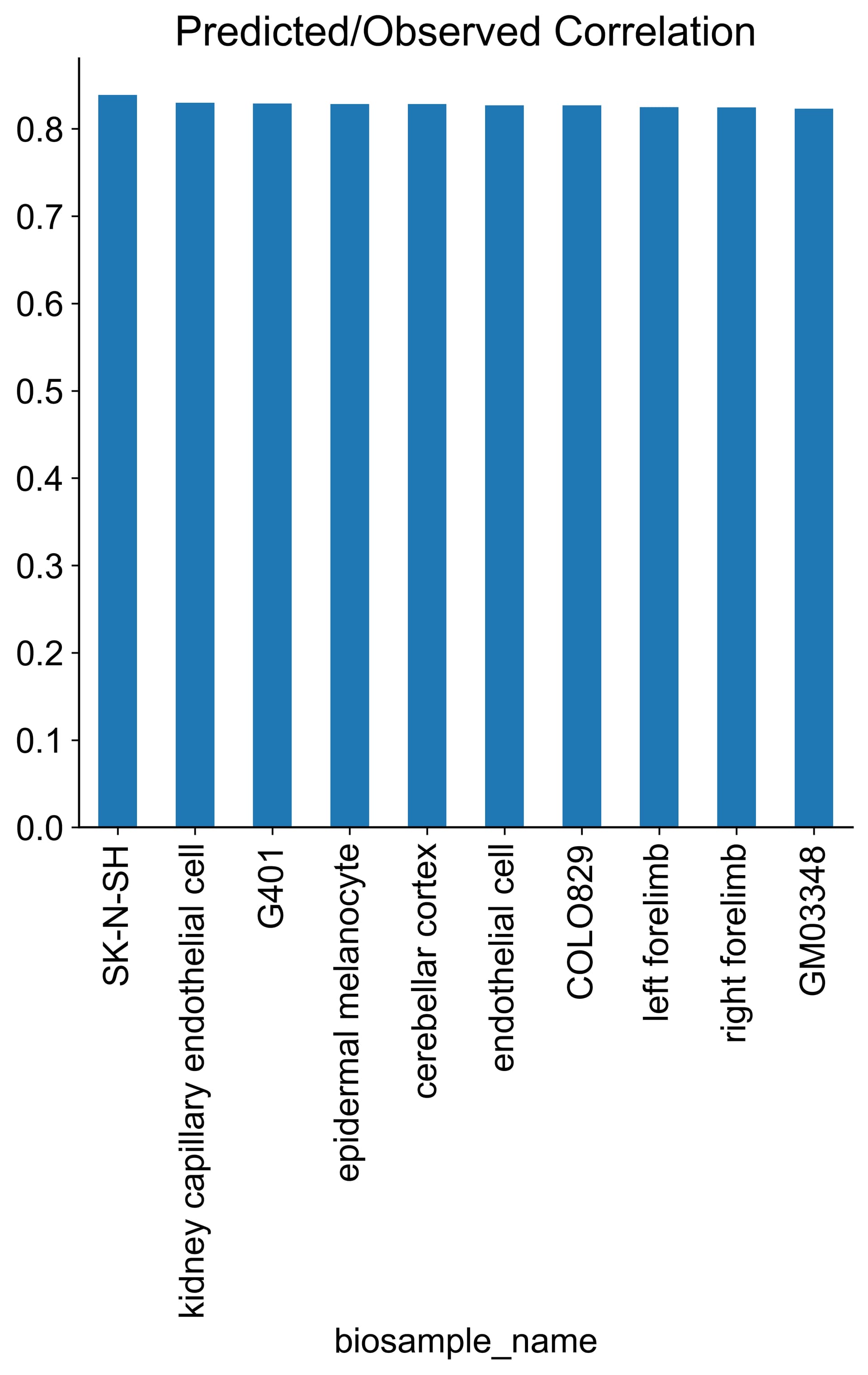
One example showing the randomness (code and data is the same, just re-runing). Top-10 performing bio samples are shown. It could be that the tissue-specificity is not really that strong here, though.